#1
ArchiveBox
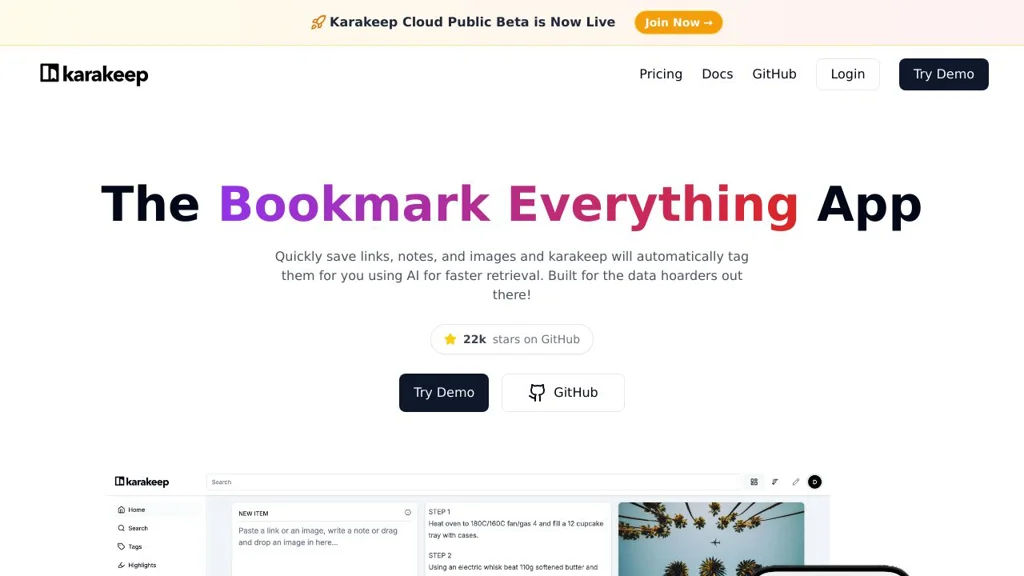
ArchiveBox helps you save and preserve web pages from bookmarks, RSS, and lists with multiple archiving methods and a searchable web UI.

ArchiveBox is a self-hosted web archiving application that turns lists of URLs (bookmarks, RSS/Atom, browser exports, text files) into a local, browsable archive. It captures pages using multiple methods to increase resilience against link rot, and provides a web UI and CLI for managing collections.
Key Features
- Ingest URLs from browser bookmarks/exports, RSS/Atom feeds, Pocket/Pinboard-style lists, and plain text
- Multi-method archiving pipeline (e.g., raw HTML, single-file snapshot, screenshots, PDF, readability/text extraction, media downloads) to improve long-term preservation
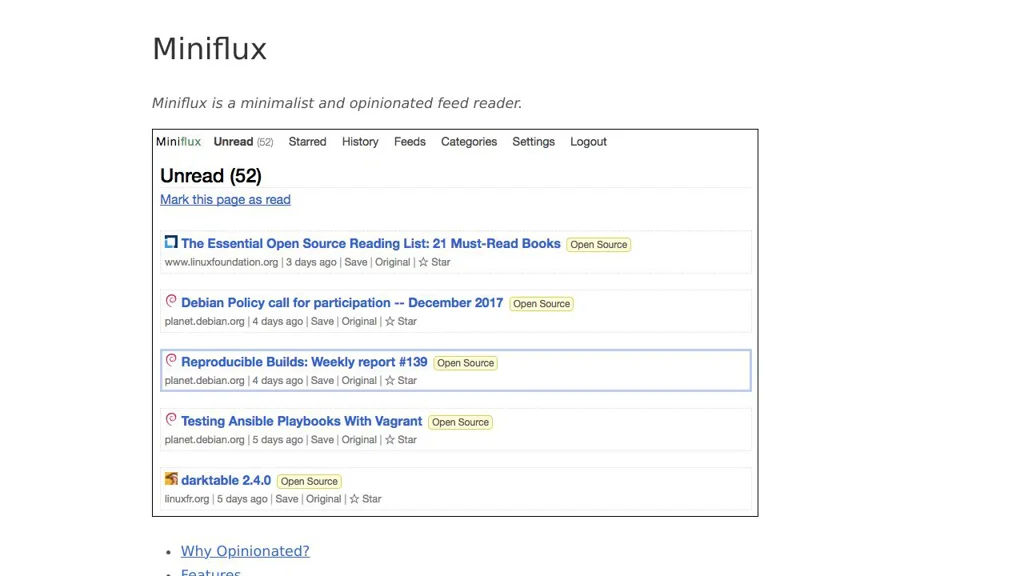
- Full-text search and filtering in the web UI, with tagging/metadata for organizing large collections
- Scheduled/automatic archiving and re-archiving via cron/queue-style workflows
- CLI-first operation plus a web interface for browsing, searching, and replaying saved content
- Extensible “extractor” architecture to enable/disable capture methods and integrate external tools
Use Cases
- Personal “read-it-later” vault that keeps offline copies of important articles and references
- Team or research group evidence collection for sources, citations, and compliance records
- Preserving documentation, vendor pages, or incident-related URLs for future auditing
Limitations and Considerations
- Archive quality depends on target-site complexity; heavy JavaScript apps may require headless-browser based capture for fidelity
- Storage can grow quickly when enabling media/video, PDFs, and screenshots across many links
ArchiveBox is well-suited for users who want durable, searchable link preservation beyond a bookmark manager. Its layered capture approach and automation options make it a practical tool for building long-lived web archives.
26.3kstars
1.4kforks